"Come back to Recurse Center!" they told me. "You'll get to write all sorts of cool code!" they said. Well I just spent two weeks writing exactly zero lines of code. It's a great feeling, seeing everyone around you create beautiful 3D graphical masterpieces or fully complete web applications while you spend twelve hours a day struggling to read technical papers that you don't even understand. This is what happens when you attempt to do things with CRDTs.
CRDT stands for "conflict-free replicated data type". Do not ask me why they aren't called CFRDTs, that is just yet another ineffable mystery that you can add to the pile. A CRDT is kinda like a normal data structure, like a string or a map. However, unlike normal strings and maps, a CRDT is designed to be shared between multiple computers in a mesh network. Any computer can make changes to the CRDT locally, and the concurrent changes from multiple computers will be seamlessly merged together. This property makes CRDTs useful for building Google Docs-style collaborative editors! It also makes a simple-sounding operation like "insert character in string" require a ten page technical document to describe correctly! Alexei Baboulevitch's fantastic blog post on collaborative document editing is 20 thousand words long. Four of these blog posts would be longer than the first Harry Potter novel. I hope he wrote the blog post using his own collaborative editor, since it would prove its performance for editing immense documents.
Anyway, the operation that have been attempting to implement is string splicing. If I have a string foobar, and I cut the foo out and paste it at the end, I get barfoo. That's a splice. If there was only one user, this would be equivalent to just deleting the characters foo and reinserting them at a new location. However — since there are multiple users of this program, we'd like any concurrent changes inside of foo to be copied over to the new location as well. For instance, if I move foo to the end and you simultaneously replace oo with aa, we'd expect the result to be barfaa. All CRDTs that I've seen so far would instead merge those two edits into aabarfoo.
I don't actually have a working splice operation yet, but these are my rough, in-progress notes on the problem and my thoughts so far.
Splicing is important for structured hypertext
Considering the difficulty of implementing a new CRDT operation, you're probably thinking: do we really need a splice? If we already have insertion and deletion operations for sequences, that gets us most of the way, right? In fact, there's even a CRDT that allows a single node of a tree — so a character or a struct — to be moved to another place in the tree. So why bother adding splice?
Let's look at todo lists. Everybody likes todo lists, right? It seems like every CRDT and UI framework under the sun implements one, so let's try to implement our own. Here's one from Dropbox Paper:

The CRDT schema I often see for this list looks somewhat like:
[
{checked: false, contents: "Hello World"},
{checked: false, contents: "This is a todo item"},
]
Assuming the contents strings in this schema are actually a CRDT sequence of characters, this should work great, right? Well looking back at the example above, what happens when we press return? In many text editors, we get an image that looks like this:

If you've read the CRDT literature, you may recognize that this presents a problem for how we've set up our schema. We can individually delete the characters in World and put them in our newly created item, but if another user concurrently inserted ! after World, the ! would remain in the first item instead of correctly moving to the second.
One solution to this is to treat the entire document as a single sequence of characters and objects. For instance, our initial schema for this list could instead look like
"{inline object checkbox}Hello World\n{inline object checkbox}This is a todo item"
This certainly solves the return-problem, since we can just insert \n{inline object checkbox} when the user presses return. Our second user's ! will get inserted in the correct place. Problem solved? Well, we now have another issue. What do we do when users reorder items?
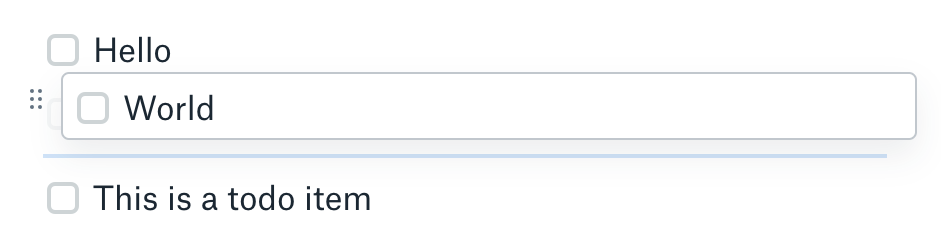
As far as I can tell, the single continuous sequence is ~roughly what Dropbox Paper does (although I believe they use operational transform instead of CRDTs), since they tend to have sync errors when todo items are concurrently edited and moved around. In the above example, if one user inserts ! at the end of World and another user moves World to a different spot in the list, there will be nothing associating the ! with the World. In Dropbox Paper, this is what you get:

I never deleted any checkboxes, but by some gimmick of the synchronization, one of our checkboxes has disappeared. If your list allows both splitting a text object in half and reordering objects, neither of these two solutions will work well. However, if we had a splice operation that moved both existing characters as well as future inserts within the range, suddenly both work! In the continuous sequence case, we can splice todo items from one part of the list to another. And in the structured case, we can splice the second half of one todo item into the string for a newly created todo item.
Splicing CRDTs could also be effectively used to better merge cut/paste operations with concurrent edits, and to track the original author of any particular character.
Prior art
Although I haven't found any prior art that implements a splicing operation, there are multiple examples of trees that allow moving nodes around, which is at least a first step. We'll look at two examples here.
Several months after Data Laced with History was written, in May 2018, some Cambridge researchers published a new CRDT called an OpSet. This is the first CRDT that allows for node movement, where a single character or item in the tree can be moved to another spot in the tree. This isn't quite the splice function we're looking for, but it's a great starting point. Let's look at their implementation. The authors identify two major issues with moving a node:
- We must ensure the resulting structure is a tree, so we have to prevent cycles.
- A node moved twice should not be duplicated in two locations.
The OpSet CRDT takes a very different approach to concurrency than Causal Trees. Rather than use an add-only tree of operations, OpSet keeps its operations as a list, ordered by logical timestamp. To get the current state of the system, the client takes an initial state and applies each operation to the state one by one. This operation list isn't append only — an edit coming in from another client will often have a timestamp prior to the most recent local one. In this case, the client state must be "rewound" back to that point in the operation list, the new operation must be added and applied, and then subsequent operations must be replayed to get the final current state of the document.
This does seem somewhat slower than Causal Trees, but allows us to support more complex editing operations. Persistent data structures also makes this rewinding faster than you might think.
OpSet defines an Assign operation to move nodes, which takes a number of arguments:
id: the node ID of a parent map or listobj: the ID of the node being movedkey: for maps, this is the map key, some literal value; for lists, this is the ID of the node immediately prior to the insertion point, or in the case where the insert is at the beginning of the list, the node ID of the list itself repeatedval: the IDs of the previous values assigned to that key, which are deleted
So how does this prevent our two issues?
- To prevent cycles, any time the Assign operation would create a cycle, it instead becomes a no-op. This isn't a commutative operation, but it works because OpSets linearizes the operations, so they don't need to commute with each other. If we were using a Causal Tree, our operations would be applied in arbitrary order, and we wouldn't be able to do this.
- To prevent duplication, any time the Assign operation moves a node twice, the last Assign operation wins.
My friend Kyle also sent me a recent blog post from Figma that explains how their CRDTs resolve the cycle problem. Figma also linearizes edits according to timestamps, but their approach has a central server that determines the timestamp of each operation. They also use this central server to resolve cycles:
Figma’s solution is to temporarily parent these objects to each other and remove them from the tree until the server rejects the client’s change and the object is reparented where it belongs. This solution isn’t great because the object temporarily disappears, but it’s a simple solution to a very rare temporary problem so we didn’t feel the need to try something more complicated here such as breaking these temporary cycles on the client.
I've been exploring more down the SpliceOp path, since I'd optimally like the resulting CRDTs to work in the absence of a central server, but it's perhaps an approach worth looking into, especially considering how many people use Figma's CRDTs every day. They also have some interesting notes on undo/redo, a topic I still have to research further.
Splicing is harder than node reparenting
Splicing presumably would be a valid operation on a JSON array as well as a string. This means all the node reparenting issues are issues for splicing as well: we have to prevent duplication and prevent cycles of parents. There are also some unique issues with splicing:
- How are the ends of the splice operation specified? by character ID?
- How are concurrent edits in that range moved to the new location?
- How do we resolve overlapping splices? What about nested splices?
Let's first look at the actual schema of a splice operation, and how the start and end of the range are specified. Initially, I thought we could just keep character IDs consistent across moves, and then specify splices in terms of a starting character ID and an ending character ID. This approach unfortunately has bad repercussions! Let's look at two simultaneous edits on the string '"hi mom 1234"'.
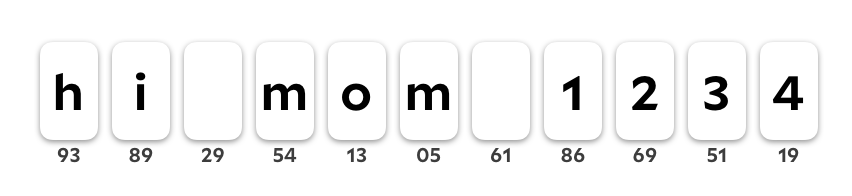
User A splices 12 to the beginning of the string.
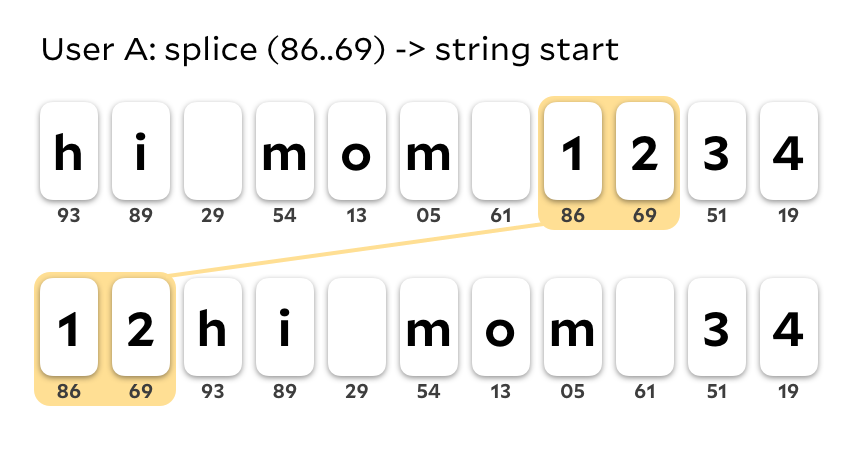
Concurrently, user B splices 23 to the end of the string.
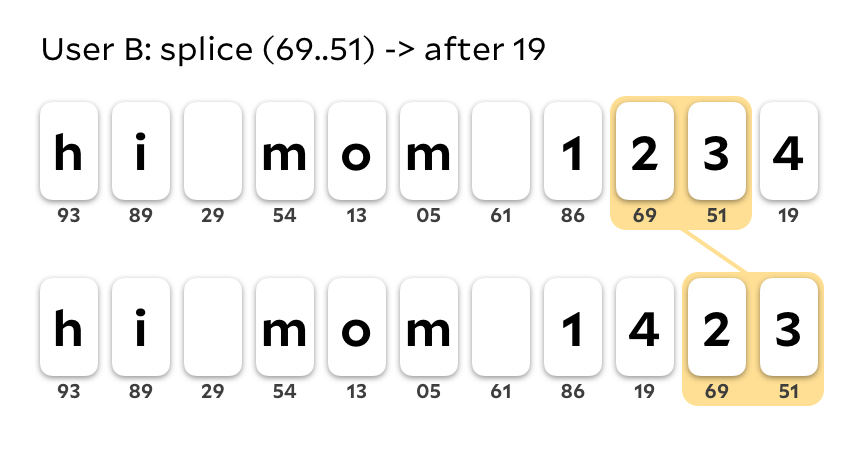
Let's say OpSet's timestamp resolution algorithm determines that user A's edit occurs after user B's. This means we apply the second edit to the output of the first, which results in this definitely very wrong edit:
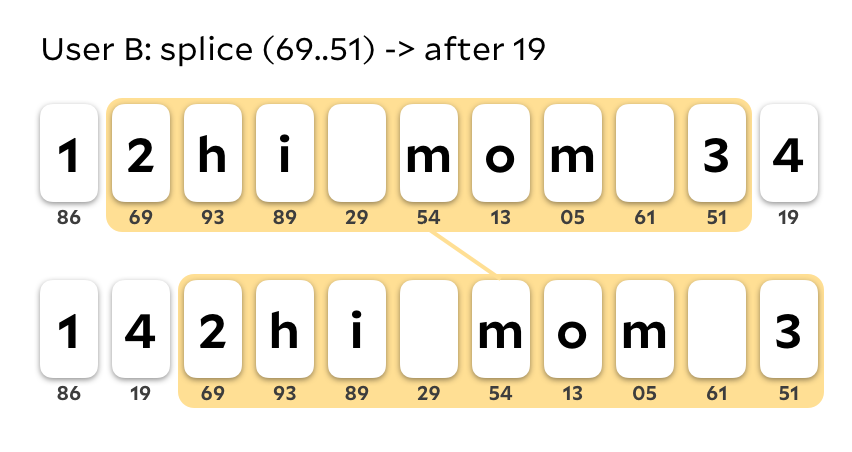
Thanks to OpSet's operation linearization, this is technically a "correct" CRDT from a mathematical standpoint, since all sites will eventually converge onto the same state. That said, it's definitely not preserving the user's intent, and would result in some very, very wacky splices, since the endpoints of splices can move around through other splices. Instead, we'd like to specify a splice operation that doesn't move with respect to other splices. If our splice operation assigned new IDs to the characters it moves, we could leave the source range as tombstones for future splice operations. But this is tricky! What IDs do we specify for the new characters? A splice doesn't have a complete list of characters in its range when it's created, since concurrent inserts could put more characters in that range. Perhaps hashing the old character ID with the ID of the splice could work?
Even with IDs for splicing that don't move around, there are still issues. If a character was deleted on one site, and then concurrently spliced twice on another site, with the second splice referencing it as a endpoint, we'd like that second splice to be able to use it as a endpoint in its new location, even though it was deleted in the original location. I think this may be resolved by having splices copy/hash even the tombstones in a range. However, this does result in worst case exponential growth of tombstones, which is obviously undesirable, especially in distributed contexts where garbage collection of tombstones is a tricky problem.
Future Work
Are splicing CRDTs possible? I'm still not 100% sure. I'm sure my sketch of an idea still has many issues beyond the exponential memory growth problem I mentioned above. Considering how useful a splicing CRDT would be, I still think this is a high value problem even after wading through several weeks of reading paper after paper. The OpSet paper that solved the node reparenting problem was only written in 2018, so clearly this is a field with plenty left to discover!
I'm starting work on an open-source implementation of the OpSets paper in Rust so that I have some base code to explore splicing CRDTs with. If I manage to make any progress, I'll post another update.
...or for a change of pace, perhaps you'd enjoy my other blog Agoraphobia →